[논문 리뷰] From SAM to CAMs: Exploring Segment Anything Model for Weakly Supervised Semantic Segmentation
Abstract
Weakly Supervised Semantic Segmentation (WSSS)은 image-level class label만 사용하여 세그멘테이션을 수행하는 것을 목적으로 한다.
최근 WSSS는 세그멘테이션 foundation 모델인 SAM(Segment Anything Model)의 발전으로 인해 눈부신 결과를 보여주고 있다. 하지만 이 방법은 여전히 class activation maps (CAMs)에서는 취약하다.
이 논문은 새로운 WSSS 프레임워크인 SAM-to-CAMs (S2C)을 제안한다. 이는 학습 중에 SAM의 지식을 직접적으로 classifier에 전달하며 CAM의 성능을 높인다.
S2C는 SAM-segment Contrasting (SSC)과 CAM-based prompting module (CPM)으로 이루어져있다.
SSC는 SAM의 자동 세그멘테이션 결과를 이용하여 prototype-based contrasting을 수행한다. 이것은 각 feature가 그 세그먼트이 프로토타입과 가깝게, 다른 프로토타입과는 멀게 제약한다.
CPM은 각 클래스 별 CAM을 프롬프트로부터 추출하고 이를 클래스 특정 세크멘테이션 마스크로 생성한다. 이 마스크는 confidence score를 기반으로한 unified self-supervision에 통합된다.
S2C는 모든 벤치마크에서 큰 마진으로 SOTA를 달성했다.
1. Introduction
Semantic Sementation은 이미지를 의미있는 세그먼트들로 나누는 task이다. Learning-based 방식은 주목할만한 발전을 이루었지만, 그들은 여전히 fully supervised approach에 의존한다. 이 문제를 해결하기 위해 Image-level 클래스 레이블을 사용하여 학습하는 Weakly Supervised Semantic Segmentation (WSSS)이 나왔다.
한편, 컨벌루션 모델은 지역을 구분짓는 classifier의 의사 결정에 중요한 역할을 하는 Class Activation Maps (CAMs)을 사용한다. CAMs는 연관된 객체에 localization을 하지만, 불완전하고 경계선에서 부정확하다.
WSSS는 이런 문제를 해결하기 위해 off-the-shelf 예측 모듈을 사용하여 추가적인 정보를 얻는다. Background-only external data, visionlanguage models 등의 사용은 경제적이면서도 의미있는 발전을 보였다.
이 논문은 최근 소개된 세그멘테이션 파운데이션 모델인 SegmentAnything Model (SAM)을 사용한다. 주목할 것은, 저자는 단지 SAM을 사용하는 것 뿐 만이 아니라 이것을 어떻게 효율적으로 사용하는 것에 초점을 맞춘다.
“from-SAM-to-CAMs (S2C)" 프레임워크는 SAM의 지식을 classifier로 전달하면서 CAMs의 성능을 높인다. 이는 SAM-Segment Contrasting (SSC) and CAM-based Prompting Module (CPM)으로 구성되어있다.
SSC는 SAM의 자동 세그멘테이션 옵션을 사용하여 세그먼트 마다 분류기 특징의 평균을 취함으로 프로토타입을 생성한다. Constrasive learning동안, 각 feature는 그 세그먼트의 프로토타입에 가깝게하고, 다른 세그먼트의 프로토타입과는 멀어지게 한다.
CPM은 SAM을 사용하여 CAM 개선한다. 각 CAM의 클래스 별로 Local peaks를 찾아서 point prompts로 사용하고 SAM을 통해 class-wise mask를 생성한다. 이 마스크를 통합된 self-supervision으로 aggregate 하기 위한 SAM의 stability score와 CAM의 activation score를 같이 고려하는 메트릭도 고안하였다.
우리는 단순하게 SAM을 사용하는 것이 아니라 효율적으로 SAM의 지식을 WSSS에 전달하는 방법을 연구했다.
2. Related Work
2.1. Weakly Supervised Semantic Segmentation
WSSS의 일반적인 파이프라인은 (1) CAM으로부터 나온 image-level class label로 모델 학습, (2) pseudo-label으로 CAM 개선, (3) pseudo-label으로 semantic segmentation 모델 학습 이다.
몇 연구들은 (2)번을 개선하기 위해 post-processing 기법을 소개했다: conditional random field (denseCRF), AffinityNet or AdvCAM. 이는 성능 개선을 보였지만, 초기의 CAM 퀄리티에 따라 노이즈하고 부정확한 activation에 취약했다.
따라서 CAMs 성능을 높이기 위한 (1) 연구가 진행되었다: cross-attention across a set of images, adversarial erasing, consistency enforcement through data augmentation, boundary-aware mechanisms, adjustment of cross-entropy loss, e integration of Vision Transformer (ViT) architecture.
2.2. WSSS with Additional Source of Information
WSSS일지라도 spatial supervision은 필요하기 때문에 외부의 지식을 사용하려는 연구가 진행되었다.
많은 연구는 상용 pre-trained 모듈을 사용했다.
- Lee et. al. [31]: 배경을 구분할 수 있는 데이터셋 제안
- Kweon et. al. [25]: 3D 포인트 클라우드 데이터 사용
Contrastive Language-Image Pretraining (CLIP)을 사용하는 최근의 방식은 효율적, 효과적이기 때문에 이 논문은 세그멘테이션 능력이 있는 SAM을 이용한다.
3. Exploring the Use of SAM for WSSS
SAM을 WSSS에 사용하기 위해 SAM에 대한 설명.
SAM은 세 가지 모듈로 구성되어있다:
1) 입력 이미지의 임베딩을 만들기 위한 이미지 인코더
2) 다양한 입력 프롬프트를 위한 프롬프트 인코더(ex: 포인트, 바운딩박스, 마스크 등)
3) 마스크 예측을 위한 디코더
SAM의 학습 목적은 입력 이미지와 프롬프트가 주어졌을 때 유효한 마스클 생성하는것이다.
주목할 것은 semantic supervision을 포함하지 않는다. 이것은 SAM이 일반적인 능력을 갖게 하며, 이미지의 의미보다 세그멘테이션 측면을 더 집중하게 한다.
또한, SAM은 자동 세그멘테이션 능력을 갖고 있어 “segment-everything”이라 표현된다.
이 능력을 이용해 CAMs로 부터 얻은 pseudo-label을 개선하는 방법이 있다. 이 방식은 간단하고 효과적이며, WSSS 방식에 사용해도 일관적인 성능을 보여준다. 그럼에도 불구하고 post-processing 방식은 pseudo-label의 노이즈에 취약하고, SAM의 예측 mask가 항상 객체의 전체 영역을 다 덮지 않기 때문에 프롬프트 세그멘테이션에 사용하기 모호하다.

다른 방식은 CLIP이나 Grounding-DINO 등 언어 모델을 사용한 zero-shot 방식이다. 단어로 된 image-level class label은 객체 인식 모델에 들어가고, 각 클래스 별로 예측된 지역은 SAM의 마스크를 얻기 위한 바운딩 박스로 처리된다. 이는 높은 성은을 보였지만, 언어 모델의 초기 예측이 잘못 될 경우 에러를 낼 수 있다.
특히 언어 모델은 일반화에 어려움을 겪는데, WSSS는 의료 영상이나 zero-shot 같은 레이블이 부족한 task에 주로 적용되기 때문에 이를 사용하는 것은 한계가 있다.
결론적으로 저자는 가장 효과적으로 SAM을 WSSS에 적용하는 방법은 이것을 CAMs의 퀄리티를 높이는 데에 사용하는 것이라고 주장한다.
4. Method
4.1. Obtaining CAMs
- G: Classifier, primarily as a CAMs generator.
- GE: encoder
- GH: classification head
- GAP: Globla Average Pooling layer to the CAMs along the spatial axes
- 멀티 레이블 분류를 위해 바이너리 크로스 엔트로피 사용
4.2. SAM-Segment Contrasting (SSC)
SAM은 신뢰할만한 세그멘테이션 결과를 보여주지만, 명백한 semantic information을 알 수 없다. 입력 프롬프트가 semantics가 아니라 위치의 집합이기 때문이다. 같은 클래스인 객체가 여러 개 등장하는 한 이미지, 예를 들어 자전거가 여러 대 겹쳐 있는 이미지인 경우 각 객체가 세그먼트 되고, 자전거들의 전체 영역을 한 개의 세그먼트로 분류하지 않는다.
다른 세그먼트에 위치한 픽셀들은 항상 다른 클래스에 속한 것이 아니다. 그래서 저자는 SAM을 logit-level 에서 바로 사용하는 것이 아니라, classifier가 featue level에서 세그멘테이션 개념을 배우는 것에 도움을 주는 것으로 사용했다.
저자는 SAM의 segmentation potential을 feature level에서 classifier에 전달해주는 SAM-Segment Contrasting (SSC)을 제안한다. 이는 주로 지역적인 prototype-based constrasive 접근 방식에 기초한다. Classifier가 어떤 픽셀이 한 개의 세그먼트로 묶어야 하는지 도움을 준다. SAM을 클러스터링 측면에서 사용하여, 분류기의 feature들을 세그먼트에 따라 대조했다(constrasting).

Figure 3은 SSC를 나타낸다. 이미지 I를 SAM으로 넣고 segment-everything 옵션을 사용해 세그먼트를 생성한다. 세그먼트가 만약 오버랩되면, 작은 세그먼트 위주로 정렬한다. 한 픽셀이 여러 세그먼트에 포함되면, 가장 작은 영역과 함께 있는 세그먼트를 택한다. 이 방식은 SE map 이라 불리는 세그멘테이션 맵을 만든다. i번째 SE map은 SEi 이다.
그와 동시에 classifier는 feature map F가 분류의 중간 결과로 나온다. Feature map의 spatial dimension이 작을수록 이를 bilinear interpolation으로 resize하여 SE map과 사이즈가 맞게 한다. 각 세그먼트 SEi에 대한 프로토타입을 세그먼트에 위치한 픽셀들의 특징을 averaging하여 생성한다. 이를 나타내면 다음과 같다.

저자는 채널에 따른 features/prototypes를 정규화하여 지속적으로 동일한 hyperspace 상에 놓여있게 했다.
각 feature가 그것에 속해있는 세그먼트의 프로토타입과 가깝게, 다른 세그먼트의 프로토타입과는 멀게 했다. 이것은 세그먼트 안에 있는 픽셀의 특징이 클러스터를 형성하게 하며, 분류기가 다른 세그먼트의 픽셀과 다른 것으로 분류하도록 도와준다. 따라서 SSC는 SAM의 세그멘테이션 지식을 feature level에서 다른 분류기로 전달하는 방식이다.
Constrasting process는 다음과 같이 정의한다.

4.3. CAM-based Prompting Module (CPM)
CPM은 SAM의 promptable 세그멘테이션 능력을 학습 중에 CAMs을 강화하기 위해 사용하는 것이 목적이다.
각 클래스 별 CAM을 SAM의 프롬프트로 사용하고, 이에 따른 클래스 특정(class-specific) 마스크를 얻는다. 모든 클래스 별 마스크는 한 개의 맵으로 합쳐지고, CAMs에 도움을 주는 self-supvervision 역할을 한다.
그러나 CAM은 score map이고, SAM에 사용되기 위한 align이 되어 있지 않다. 그래서 CAM을 SAM의 프롬프트 타입에 맞도록 변환하는 작업이 필요하다.
가장 직관적인 방법은 CAM을 이분화하여 바이너리 마스크를 만들고 이를 SAM의 마스크 프롬프트로 사용하는 것이다. 그러나 공식적으로 발표된 SAM은 이 마스크 프롬프트를 사용할 때 성능이 좋지 않다.
박스 프롬프트를 사용하는 것도 여러 문제점이 있다.
(1) 연속적인 score map을 이산적인 박스 프롬프트로 바꾸는 것은 임계값에 민감하며, 튜닝 하는데 어려움이 있어 WSSS에 맞지 않다.
(2) 이미지에 있는 객체의 개수를 모르기 때문에 잠재적으로 여러 객체를 갖고 있는 이미지는 다른 문제를 야기할 수 있다. 예를 들어, CAM이 여러개의 local minima(peaks)를 보일 때, 모든 peaks를 다 커버하는 하나의 큰 바운딩 박스를 쓸지, 각 peaks 별 바운딩 박스를 쓸지 결정해야한다.
따라서 마스크나 바운딩 박스보다는 포인트를 사용하였다. Local maximum filter(LMF)를 CAMs에서 여러 개의 peaks를 추출하는 데 사용했다. Pc는 peaks의 집합이다.

임계값 τ 보다 작은 score를 가진 peaks는 제거하였다. 피크가 여러 개라면, 같은 클래스의 객체가 여러 개 있는 것이다. Figure 4. 참조.
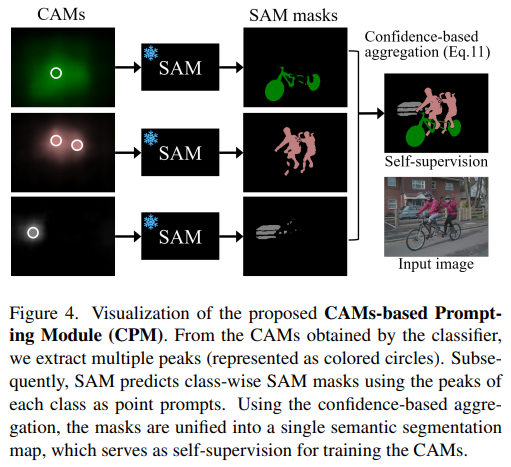
peaks를 포인트 프롬프트로 사용하고 얻는 정제된 class-specific 마스크는 다음과 같다.

높은 stability score를 가진 픽셀은 주어진 프롬프트로 세그멘테이션 될 가능성이 더 높다.
효율성을 위해 모든 학습 데이터에 대해 SAM 인코더는 한 번만 실행하고, 얻어진 임베딩과 class-wise 포인트 프롬프트로 디코딩하였다.
생성된 class-specific mask는 한 개의 세그멘테이션 맵으로 합쳐지는데 Figure 5. 에 보인 것 처럼 마스크는 종종 겹친다. 그 이유는 CAMs와 SAM의 에러 때문이다.

따라서 이 논문은 새로운 confidence-based aggregation 방식을 제안한다. 이는 마스크가 겹쳐도 각 픽셀이 적절한 클래스로 분리되도록 한다. 기존 클래의 SAM과 CAMs의 연관성을 고려하여 SAM stability인 $ α_{sam}^c $를 reliability score map으로 얻었다. 또 CAMs를 위해서는 각 클래스 별 SAM 마스크 위에서의 CAM activation을 다음과 같이 구했다.


Confidence는 다음과 같이 정의된다.
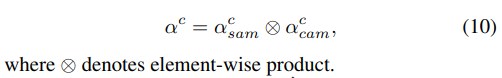
통합된 세그멘테이션 맵은 다음으로부터 얻어진다.

얻어진 S햇은 CAMs를 학습하기 위한 self-supervisory 신호이다. Foreground 클래스인 C로 정의되는 CAMs와는 다르게 이것은 background class도 포함한다. 배경 개념을 CAMs의 학습에 넣기 위해, background score map인 A^0 을 다음과 같이 표현한다.
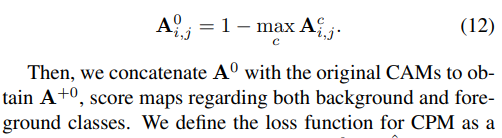
CPM을 위한 loss function은 cross entropy이다.

따라서, 이 논문에서 제안한 S2C 프레임워크의 전체 loss function은 다음과 같다.

5. Experimental Results
5.1. Dataset and Evaluation Metric
Dataset
- PASCAL VOC 2012: 1464/1449/1456 images for the train/val/test sets, 20 foreground classes and a background class, 10582 images along with image-level classification labels.
- MS-COCO: 80k/40k images for the train/val sets, 80 foreground classes and a background class.
Evaluation Metric
- mean Intersection over Union (mIoU)
5.2. Implementation Details
- Feature encoder of classifier: resnet38
- Semantic segmentaion model: Deeplab with R38 backbone
- SAM: ViT-H model
- Data augmentation: horizontal flipping, random cropping/resizing, and color jittering
- poly learning rate , which multiplies (1 − iter max iter ) 0.9 to the initial learning rate (0.02)
- L_CPM 은 처음 에폭크부터 넣지 않음. 초기에 CPM은 에러가 많기 때문
- τ and T to 0.5
5.3. Ablation Studies

Table 1. 을 보면 SSC만 사용해도 성능이 많이 오른다. feature-level에서 사용하는 것이 logit-level에서 사용하는 것 보다 더 좋다.
입력 이미지가 SE map에서 over-segmented 되면 다른 세그먼트에



