[데이터셋 소개] VGG-SOUND: A LARGE-SCALE AUDIO-VISUAL DATASET
https://arxiv.org/pdf/2004.14368
https://github.com/hche11/VGGSound?tab=readme-ov-file
GitHub - hche11/VGGSound: VGGSound: A Large-scale Audio-Visual Dataset
VGGSound: A Large-scale Audio-Visual Dataset. Contribute to hche11/VGGSound development by creating an account on GitHub.
github.com
ABSTRACT
대규모의 오디오-시각 데이터셋을 만드는 것이 목표.
오디오 인식 모델의 학습과 평가에 사용 가능.
오픈소스 미디어(유튜브)로부터 컴퓨터 비전 기법을 이용하여 만듬.
1. INTRODUCTION
- AudioSet: 대규모 오디오-시각 데이터셋, over 2milion clips, 비제약조건
기존 데이터셋은 사람의 노동이 많이 필요함.
목적은 실 상황에서 얻어진 소리들로 구성된 대규모 데이터셋을 만드는 것.
컴퓨터 비전 기술을 사용하여 오디오-시각 상호연관성을 보장하고 낮은 노이즈와 적은 노동력이 드는 데이터셋을 만들었다.
- Contriution
1. 자동, 변경 가능한 파이프라인으로 생성된 'in the wild' 오디오-시각 데이터셋
2. VGG-Sound, 200K clips, 309 audio classes from 유튜브
3. 이 데이터셋에 대한 베이스라인 모델 성능 제공
2. RELATED WORK
- Audio and audio-visual datasets.
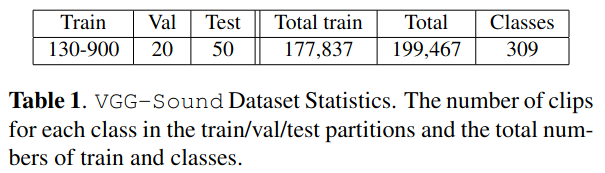
오디오 데이터셋 종류는 아래 표.

- UrbanSound: 8k 넘는 도시 소리, 10개 클래스
- Mivia Audio Events: 감시 용도
등등의 데이터셋은 클린하지만, 딥러닝 네트워크를 학습시키기에는 수량이 적다.
그래서 구글에서 AudioSet 발표. 유튜브에서 2 million 넘는 clips 가져옴. 오디오-시각 멀티모달. 그러나 이 데이터셋을 제대로 사용하기 위해선 인간의 필터링이 많이 필요함. AVE는 이를 수동적으로 정제한 작은 데이터셋.
- Audio Recognition.
- Gaussian Mixture Models (GMM)
- Support Vector Machines (SVM)
- Mel Frequency Cepstrum Coefficients (MFCCs)
- CNNs or RNNs
3. THE VGG-SOUND DATASET
VGG-Sound contains over 200k clips for 309 different sound classes.

Sound classes can be loosely grouped as: people, animals, music, sports, nature, vehicle, home, tools, and others.
다음은 이 데이터셋을 만든 과정 설명. 다음 테이블은 과정을 거치면서 변한 클래스, 비디오 클립 개수 보여줌.

Stage 1: Obtaining the class list and candidate videos.
먼저 데이터셋에 있는 잠정적인 소리 클래스들을 파악해야 한다. 이 리스트를 만들기 위해 세 가지 원칙을 적용했다.
1. 소리는 in the wild 해야 하고, 실생활의 소리여야 한다.
2. 소리를 시작적으로 구분할 수 있어야 한다. 즉, 이미지만 보고도 소리의 근원지가 어딘지 합리적으로 예측 가능헤야 한다. 예를 들어, ‘electric guitar’ 소리는 누군가 기타를 치는 모습으로 알아볼 수 있다. 그러나 'happy song’ and ‘pop music’ 인지 여부는 알 수 없다. 따라서 이와 같은 클래스는 데이터셋에 포함될 수 없다.
3. 소리는 서로 배타적이어야한다. 레이블은 현존하는 오디오 데이터셋 클래스들의 가장 리프 노드만으로 이루어져 있다. 각 클립마다 한 개의 레이블을 갖고있다. 예를 들어, 차 엔진 소리를 담고 있는 클립이라면 레이블은 “car engine”이지 그냥 "engine"이 아니다.
이런 방식으로 얻어진 클래스는 600개이다. 각 클래스 이름은 유튜브에서 자동으로 찾았다.
Stage 2: Visual verification.
이 단계의 목적은 시각적 상징물을 찾아내는 것이다.
각 오디오 클래스 마다 이에 상응하는 시각적 상징은 이미지 classifier를 통해 주어진다. 예를 들어, ‘playing violin’ and ‘cat meowing’은 OpenImage classifier의 ‘violin’ and ‘cat’으로 매치된다.
그러나, VGG-Sound 클래스의 반(‘hail’, ’playing ukulele’ 등) 은 OpenImage classifiers로 바로 매칭할 수 없다.
이 문제를 해결하기 위해, 소리 레이블이 시각 레이블로 매치되는 방식으로 semantic word embeddings를 사용했다.
600개 소리 클래스와 5000개의 OpenImage 클래스를 word2vec 임베딩으로 바꿨다. 이 임베딩은 512 디멘션을 갖고 있다.
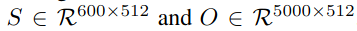
그 다음 코사인 유사도를 계산해 affinity matrix를 만들었다. 이는 소리와 시각의 유사도를 나타낸다.

600개의 소리 클래스의 각각 상위 20개 OpenImage 클래스는 시각 상징으로 선택된다. 예를 들어, 'hail’은 'nature,
nature reserve, rain and snow mixed, lightning, thunderstorm, etc.’ 등으로 매칭되고, 'playing electric guitar’ 는 ‘electric guitar, guitar, acoustic-electric guitar, musical instrument, etc’ 등으로 매칭된다.
이 연관성이 정의되면, OpenImage pre-trained classifier가 비디오를 다운로드하고, 가장 높은 예측 스코어를 가진 10 프레임이 뽑힌다. (절댓값 0.2 임계값) 클립은 이 프레임 앞뒤 5초로 생성된다.
이 과정을 거친 뒤 600클래슨느 470이 되었다.
Stage 3. Audio verification to remove negative clips.
많은 클립들은 객체의 소리도 있지만 인간, 나레이셔느 혹은 배경 음악 등의 소리가 함께 있는 것을 발견했다.
VGGish 모델을 이용하여 세 가지 소리 클래스로 분류했다: 말, 음악, 그 외.
Finetuned된 classifier를 사용하여 임계값 0.5로 클립을 정제했다. 예를 들어, 'playing bass guitar’ 비디오에서 "speech”가 임계값보다 더 크면 제거하고, 음악은 제거하지 않았다. 'dog barking’ 비디오에서는 speech and
music이 제거되었다.
이 과정을 거친 뒤 390 클래스가 남았다.
Stage 4: Iterative noise filtering.
각 클래스 별로 20개의 비디오가 랜덤하게 뽑히고, 수동으로 검수된다.



