[논문 요약] Sound Source Localization is All about Cross-Modal Alignment
https://arxiv.org/pdf/2309.10724
Abstract
인간은 이미지에서 소리의 근원지를 쉽게 알 수 있다. 이 task를 "sound source localizaion"이라 칭한다.
이 논문은 SOTA localization 성능을 보여주는 audio-visual cross-modal semantic understanding 기법을 소개한다.
1. Introduction
인간은 쉽게 소리의 근원지를 알 수 있으며, 이벤트를 쉽게 이해할 수 있다.
인간의 인식 기법에 착안한 기존의 모델들은 audio와 visual 신호에 상관이 있다고 가정했다.
이 가정을 기반한 여러 unsupervised 방법들이 있었지만, 사실은 supervisedly vision networks를 사용한다거나, object detector를 전처리로 사용하는 행위 등, 내면에 supervised 요소들을 포함하고 있었다.
이런 initial representations을 사용하면 성능 저하가 있을 수 있기 때문에 이전 기법들은 완전한 self-supervised 방식이 아니었다.
게다가, 최근의 방식들은 visual - audio 신호의 상호작용(interaction) 없이 visual 신호만으로도 localization을 잘 수행하는 것을 보여줬지만, 이 방식은 sound source localization task의 진짜 목적이 아니었고 진짜 소리의 근원지를 찾아내는 것이 아니었다.
따라서 이 논문에서는 cross-modal retrieval task를 부가적인 sound source localization 평가 방식으로 삼는다. 이 작업을 통해서 audio-visual modality가 정확하게 상호작용 하고있는지 측정할 수 있다. 우리의 실험은 높은 sound source localization 성능이 높은 cross-modal retrieval 성능을 보장하지 않는다는 것을 보여줬다.
또한, sound source localization의 cross-modal semantic understanding에 도움을 주는 semantic alignment를 제안한다.
2. Related Works
Sound Source Localization
Sound source localization은 audio-vision 모달리티 간 상호관계를 활용하기 위해 조사되었다.
가장 보편적으로 사용되는 방법은 cross-modal attention with contrastive loss 이고 이후 attention-based 방식들이 발전되었다.
몇몇 방식들은 semantic label을 encoder의 pretrain으로 사용하거나 object prior를 사용했다.
그러나 object prior 방식은 vision 정보만 사용하기 때문에 fals positive output을 낼 수 있었다.
3. Method
3.1. Preliminaries
Constrasive Learning
positive와 negative pair로 representation을 학습한다.
Encoded query 샘플 q와 encoded positive pairs k+, negative pairs k가 있다고 가정하면 loss는 다음과 같이 정의된다.
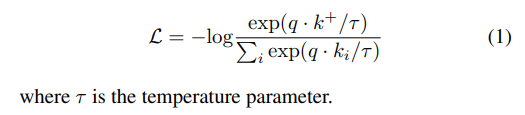
Cross-modal constrasive Learning
Constrasive learnig을 multiple modalities로 확장한 것이다.
Sound source localization에서는 audio-visual 상호관계를 positive-negative cross modal pairs로 정의한다.

3.2. Cross-Modal Feature Alignment
이 논문은 spatial localization과 semantic feature alignment를 같이 고려한다.
그러기 위해, 두 가지 similarity funstions를 사용했다, $ S_L $, $ S_A $.
$ S_L $은 localization을 위해, $ S_A $는 cross-modal feature alignment를 위해 사용했다.

논문에서는 실험을 통해 강한 localization 성능이 semantic understanding을 보장하지 않는다는 것을 발견하여, instance level의 constrasive loss를 추가하였다. 이는 장면의 전체 컨텍스트를 캡슐화하여 더 나은 audio-visual semantic alignment를 제공한다.
그러나, instance level constrasting은 spatial discriminativeness를 더 smooth하게 만들 수 있기 때문에 projection layer를 추가하였다. 이는 localization과 semantic alignment의 latent space를 분리한다.
Cross-modal feature alignment를 위한 simliarity function은 다음과 같이 정의된다.

avg(): spatial average pooling, $ p_v $: projection layer for visual features, $ p_a $: projection layer for audio features.
3.3. Expanding with Multiple Positive Samples
일반적으로 contrasive learning은 한 개의 positive pair와 여러개의 negative pair들 사이를 대조한다.
audio-visual learning에서는 같은 clip으로부터 나온 audio-image pair는 positive pair로, 다른 clip으로부터 나온 것은 negative pair로 간주한다.
그러나, 단일 인스턴스 식별 만으로는 강력한 cross-modal alignment를 달성하는데 충분하지 않을 수 있다.
저자는 constrasive learning을 single-instance 보다 positive set을 구축하고, 그들을 pairing하는 방식으로 바꿨다. positive set을 구축하기 위해 각 모달리티 별로 hand-crafted 와 conceptual positive 샘플들을 포함하였다.
- Obtaining hand-crafted positive samples.
self-supervised representation learning에서 랜덤하게 aumented된 positive multi-view pairs를 사용하는 것은 흔한 일이다. 이와 비슷하게, 저자는 single-anchor audio-image pair를 각 모달리티 별 간단한 증강 기법(일반적인 이미지 transformations, temporal shifting to audios)을 적용하여 multiple positive pair로 확장한다.
sound source localization은 semantic consistency로부터 학습되는거지 비디오의 시간 차이로부터 학습 되는 것이 아니기 때문에 이런 증강 기법이 가능하다. 살짝의 temporal shift in audio는 contextual information을 크게 바꾸지 않는다.
- Obtaining conceptual positive samples.
저자는 개념적으로 비슷한 샘플들로 구성된 positive set도 포함하였다.
개념적으로 비슷한 샘플을 고르기 위해 저자는 사전 학습된 인코더로부터 샘플링한 k-nearest neighbor search를 사용하였다.
이미지와 오디오 쌍이 주어지면, 다른 샘플들과 코사인 유사도(cosine similarity)를 계산하고, 가장 비슷한 top-k 를 찾는 것이다. 이 k개의 샘플에서 한 개를 뽑아 conceptually similar 샘플을 얻는다.; $ v^conc$ , $ a^conc$ .
이를 positive samples로 사용하면 모델의 semantic understanding을 확장할 수 있다.
- Pair Construction.
각 모달리티 별로 hand-crafted 그리고 conceptual positive 샘플을 얻으면, 9개의 구별된 audio-visual pairs를 얻을 수 있다.; $ V = \{v, v^{aug}, v^{conc}\} $ and $ A = \{a, a^{aug} , a^{conc}\} $. 이것은 constrasive learning을 통한 그들간의 semantic alignment와 일관성을 보장한다.
negative pairs는 남아있는 샘플들 중에서 랜덤하게 선정된다. 이 페어들 중에서는 hand-crafted 이던지conceptually 이던지 상관이 없다.
3.4. Training
loss function에는 localization, instance-level simliarity functions, multiple positive pairs 가 다 포함되어 있다.
최종 loss term은 다음과 같다.
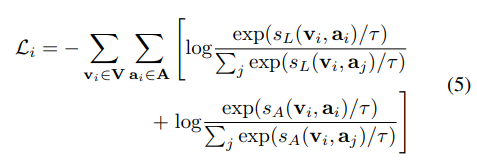
4. Experiments
이 모델은 VGGSound and SoundNet-Flickr 데이터셋으로 증명되었다.
4.1. Experiment Setup
- Datasets.
VGGSound, SoundNet-Flickr-144K로 학습
- VGGSound: audio-visual dataset / 200k videos
- SoundNet-Flickr-144K: SoundNet-Flickr의 서브셋
학습 뒤에는 VGG-SS, SoundNet-Flickr-Test로 성능평가. 이 evaluation sets는 sound source의 바운딩 박스 정보가 있다.
또한, 추가적인 평가를 위해 AVSBench, Extended VGGSound/SoundNetFlickr 도 사용.
- AVSBench: binary segmentation map을 제공하여 audio-visually 연관된 픽셀을 보여준다.
- Extended VGGSound/SoundNetFlickr: 주로 non-visible sound sources를 찾기 위해 사용된다.
- Implementation details.
오디오-비디오 인코딩을 위해 두 개의 resnet18 모델을 사용하였다. 이전 기법과는 다르게, visual 인코더로 fine-tune이나 pretrained 모델을 사용하지 않고, 오디오와 비전 둘 다 스크래치부터 학습하였다.
이미지와 오디오는 이전 방식에 따라 전처리하였다. (Localizing visual sounds the hard way(CVPR, 2021), Learning sound localization better from semantically similar samples(ASSP, 2022))
multiple 페어를 생성하기 위해 NN search와 일반적인 증강 기법들을 사용하였다.
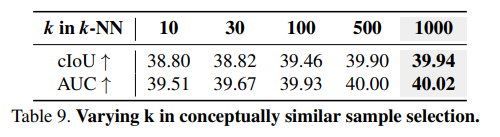
NN search에서 k개의 conceptually 비슷한 샘플을 얻기 위한 두 가지의 setup 실험을 진행하였다.
(1) supervisedly pretrained encoder: resnet과 VGGSound를 각각 사용.
(2) self-supervisedly pretrained encoder: CLIP 비전 인코더, Wav2CLIP 오디오 인코더 사용.
k=1000으로 실험.
이미지 증강을 위해서, SimCLR을 사용하였고, 오디오 증강을 위해서는 시간축으로 랜덤하게 shift 하였다.
모델은 50에폭동안 학습되었고, Adam Optimizer, lr=0.0001, constrasive learning에서 τ=0.07로 설정하였다.
4.2. Quantitative Results
- Comparison with strong baselines.
1. VGGSound-144K로 학습하고 VGG-SS and SoundNet-Flickr test sets에 평가
2. SoundNet-Flickr-144K로 학습하고 SoundNet-Flickr test set에 평가
위 두 실험은 같은 양의 데이터로 학습됨. 실험 결과는 아래와 같음.
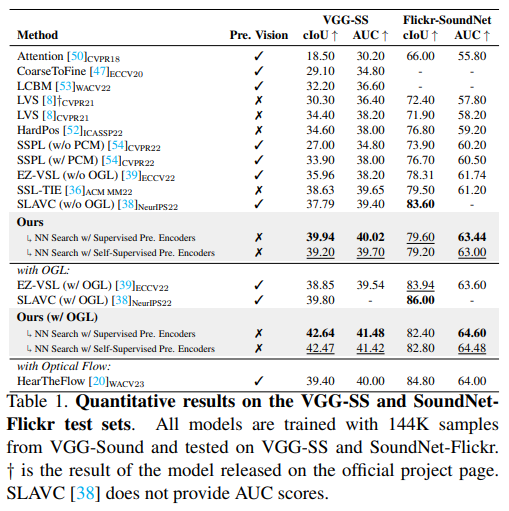
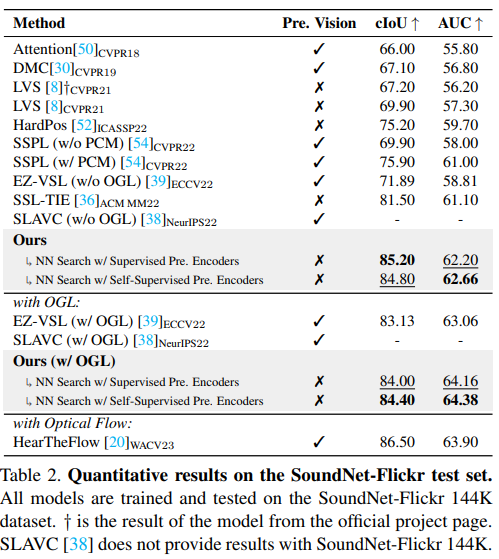
이 모델 성능이 가장 좋았고, 특히 비전 인코더에 pretrained를 사용하지 않았음에도 SOTA를 달성한 것은 유의미하다. 이런 결과가 나온 이유는, Mo et al. [38]에서 논의된 바와 같이, supervisedly pretrained 비전 인코더를 사용하는 것은 sound source localization 문제를 weakly supervised 문제로 만들기 때문이다. pretrained 비전 인코더를 사용하지 않아도 우리 모델은 table 1, 2 에서 모두 SOTA 성능을 달성했다.
추가적으로 이전의 여러 methods들과 비교했을 때 우리의 결과는 해당 methods이 필요하지 않다는 것을 발견했다. background noise를 줄이기 위해 PCM 모듈을 사용한 SSPL 방식, optical flow를 사용한 HTF 방식, pretrained된 visual 인코더로 얻어진 object guidance를 통해 초기의 audio-visual localization 결과를 정제한(a.k.a. OGL) EZ-VSL 방식 등을 사용하지 않아도 우리의 모델은 SOTA 성능을 달성했다. 이는 추가적인 semantic and multi-view correspondence(아마 추가한 positice set을 말하는듯?)들이 강력한 supervision을 주었다는 것을 의미한다.
Optical flow 모달리티를 추가하여 HearTheFlow 모델과 비교했을 때, VGGSS test set에서는 성능이 더 좋았지만, SoundNet-Flickr test set에서는 더 낮았다. 대신에 더 나은 audio-visual correspondence와 alignment에 의존한다. (라고 하는데 이에 대한 근거는 어디??)
4.3. Ablation Results
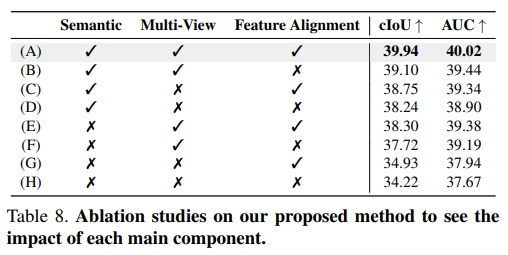
- Retrieval.
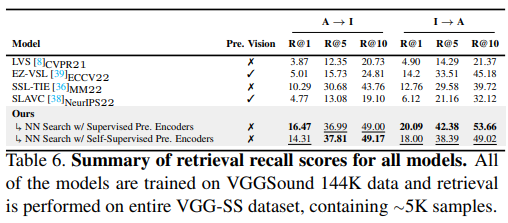
cross-modal retrieval 능력을 평가하기 위해 VGG-SS 데이터셋을 사용.
table 6. 에서 볼 수 있듯이 SOTA.
EZ-VSL은 cross-modal retrieval에서 SLAVC보다 더 성능이 좋지만, sound source localization에서는 SLAVC이 더 성능이 좋았다.(table 1. 참고) 이것은 좋은 sound localization 성능이 좋은 audio-visual semantic understanding을 보장하지 않는다는 것을 보여준다.
4.4. Qualitative Results
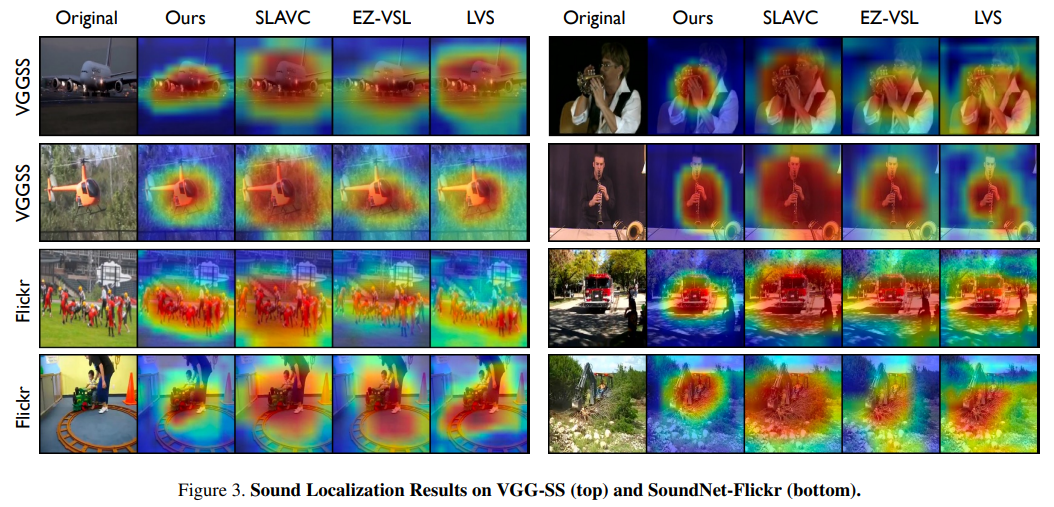
다른 메소드들보다 localization 범위가 더 작다.(=더 정확하다.)
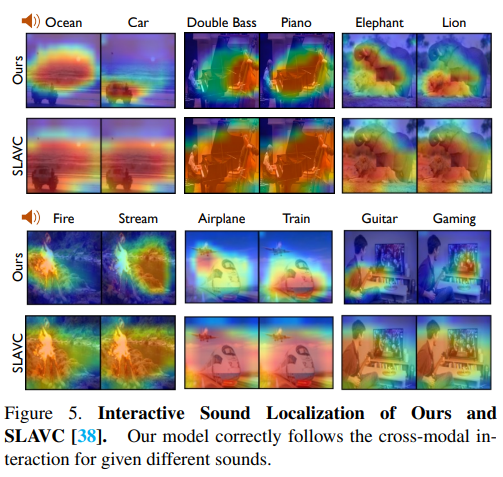
cross-modal semantic understanding의 중요성
cross-modal interaction을 시각화하면 한 개의 씬에서 다른 소리에 따라 다른 위치에 localized 되는 것을 볼 수 있다. 이것은 SLAVC보다 이 모델이 소리에 따라 다른 물체를 더 잘 localization 한다는 것을 알 수 있다.
5. Conclusion
이 연구에서 저자는 sound source localizaion에서의 높은 성능이 꼭 cross-modal retrieval에서의 높은 성능을 보장하지 않는다는 것을 밝혔다. localization능력을 가져가면서 audio-video 페어 사이의 semantic alignment를 가져가지 위해 multi-view audio-video pairs를 제안했다. 이 연구는 localization과 cross-modal understanding 둘 다 좋은 성능을 보인다.



