최신 글
-
[2025 취업] 2025년도 AI 분야 지거국 출신 상반기 취뽀 후기(Thank You, Lord)
[2025 취업] 2025년도 AI 분야 지거국 출신 상반기 취뽀 후기(Thank You, Lord) 이럴수가 저럴수가 세계적인 대 혼란의 시대에IMF 때보다 취업하기 어렵다는 이 시대에최종 합격을 하다니!!!!너무 기쁘고 감사하다 ㅎㅎㅎ이 감정을 그대로 남기기 위해 포스팅한다. 스펙- 지거국 공대 학사 수석 졸업, 인공지능 석사 전공- 학부 기간 동안 인턴 2회, 졸업 이후 정출연 연구 경력 3년- 토익 855, 오픽 IH, 기사 자격증 1개- SCIE 논문 1편, 국제 학술대회 논문 2편- 현재 만 나이로 20대 중반 근무 중인 연구소 계약 종료 시점 6개월 전부터 취업 준비했다.그래서 계약 종료 직전에 최종 합격 소식을 받았다 ㅎㅎ(나이스) 서류 지원 개수, 서합 개수, 필합 개수, 필탈 개수, ..
2025.05.20
-
 [리눅스/Linux] 하위 디렉토리 별 용량 보기 / 특정 용량 이상 폴더 찾기
[리눅스/Linux] 하위 디렉토리 별 용량 보기 하위 디텍토리 별 용량 보는 명령어du -sh * | grep 'G' du -sh *: 현재 경로의 하위 항목 용량 확인grep 'G': GB 단위 항목만 표시 필자의 실행 결과는 다음과 같다. 특정 용량 이상인 폴더 찾기예를 들어, 2기가 이상인 폴더를 찾는다면 다음의 명령어를 입력하면 된다.du -sh * | awk '$1 ~ /G/ && $1+0 > 2'
2025.04.09
[리눅스/Linux] 하위 디렉토리 별 용량 보기 / 특정 용량 이상 폴더 찾기
[리눅스/Linux] 하위 디렉토리 별 용량 보기 하위 디텍토리 별 용량 보는 명령어du -sh * | grep 'G' du -sh *: 현재 경로의 하위 항목 용량 확인grep 'G': GB 단위 항목만 표시 필자의 실행 결과는 다음과 같다. 특정 용량 이상인 폴더 찾기예를 들어, 2기가 이상인 폴더를 찾는다면 다음의 명령어를 입력하면 된다.du -sh * | awk '$1 ~ /G/ && $1+0 > 2'
2025.04.09
-
No module named 'MultiScaleDeformableAttention'
https://github.com/fundamentalvision/Deformable-DETR/issues/22 No module named 'MultiScaleDeformableAttention' · Issue #22 · fundamentalvision/Deformable-DETRHow should I deal with this problemgithub.com Deformable attention module 사용 관련 생긴 오류. 해결 방법은 경로 내에 있는 make.sh 돌리는것.
2025.03.14
-
 [리눅스/Linux] 백그라운드 실행 중인 파이썬 프로세스 확인 명령어
[리눅스/Linux] 백그라운드 실행 중인 파이썬 프로세스 확인 명령어 서버에 학습을 돌릴 때 터미널이 종료되어도 학습이 지속되도록 하는 방법 중 하나는 백그라운드 실행이다. 백그라운드 실행을 종료하기위해선 를 알아야 한다. 가장 보편적으로 PID를 알아내는 방법은 'ps' 명령어 사용이다. -al, -af 등 플래그를 붙여서 사용 가능하다. psps -afps -al 그런데 setsid 를 사용한 백그라운드 실행 시 ps -af, ps -al 등 다른 프로세스를 확인하는 명령어로는 프로세스가 출력되지 않는다. 이럴 때는 실행 중인 파이썬 프로세스를 불러와서 확인해볼 수 있다. 파이썬 프로세스 확인 명령어 ps aux | grep python 명령어를 입력하면 파이썬으로 실행 중인 모든 프로세스가 나온다..
2025.03.14
[리눅스/Linux] 백그라운드 실행 중인 파이썬 프로세스 확인 명령어
[리눅스/Linux] 백그라운드 실행 중인 파이썬 프로세스 확인 명령어 서버에 학습을 돌릴 때 터미널이 종료되어도 학습이 지속되도록 하는 방법 중 하나는 백그라운드 실행이다. 백그라운드 실행을 종료하기위해선 를 알아야 한다. 가장 보편적으로 PID를 알아내는 방법은 'ps' 명령어 사용이다. -al, -af 등 플래그를 붙여서 사용 가능하다. psps -afps -al 그런데 setsid 를 사용한 백그라운드 실행 시 ps -af, ps -al 등 다른 프로세스를 확인하는 명령어로는 프로세스가 출력되지 않는다. 이럴 때는 실행 중인 파이썬 프로세스를 불러와서 확인해볼 수 있다. 파이썬 프로세스 확인 명령어 ps aux | grep python 명령어를 입력하면 파이썬으로 실행 중인 모든 프로세스가 나온다..
2025.03.14
-
 [기술 정리] Speaker Recognition, 화자 인식에 대한 조사 및 알아둘 내용 정리 노트
연구를 위한 기술 조사 과정에서 개인적으로 알아두면 좋을 것 같은 내용을 정리한 문서. 논문 조사A review on speaker recognition: Technology and challengeshttps://www.sciencedirect.com/science/article/pii/S00457906210003182021년도 서베이 논문- Human speech can provide much information as the human voice forms a vital characteristic of an individual. Accent, language, speech, emotion, gender, and the speaker’s identity are some of the informatio..
2025.03.13
[기술 정리] Speaker Recognition, 화자 인식에 대한 조사 및 알아둘 내용 정리 노트
연구를 위한 기술 조사 과정에서 개인적으로 알아두면 좋을 것 같은 내용을 정리한 문서. 논문 조사A review on speaker recognition: Technology and challengeshttps://www.sciencedirect.com/science/article/pii/S00457906210003182021년도 서베이 논문- Human speech can provide much information as the human voice forms a vital characteristic of an individual. Accent, language, speech, emotion, gender, and the speaker’s identity are some of the informatio..
2025.03.13
-
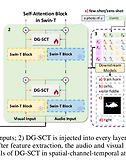 [논문 요약] Cross-modal Prompts: Adapting Large Pre-trained Models for Audio-Visual Downstream Tasks
[논문 요약] Cross-modal Prompts: Adapting Large Pre-trained Models for Audio-Visual Downstream Tasks 2023 NeurIPShttps://arxiv.org/abs/2311.05152 Cross-modal Prompts: Adapting Large Pre-trained Models for Audio-Visual Downstream TasksIn recent years, the deployment of large-scale pre-trained models in audio-visual downstream tasks has yielded remarkable outcomes. However, these models, primarily tra..
2025.03.04
[논문 요약] Cross-modal Prompts: Adapting Large Pre-trained Models for Audio-Visual Downstream Tasks
[논문 요약] Cross-modal Prompts: Adapting Large Pre-trained Models for Audio-Visual Downstream Tasks 2023 NeurIPShttps://arxiv.org/abs/2311.05152 Cross-modal Prompts: Adapting Large Pre-trained Models for Audio-Visual Downstream TasksIn recent years, the deployment of large-scale pre-trained models in audio-visual downstream tasks has yielded remarkable outcomes. However, these models, primarily tra..
2025.03.04
-
TensorFlow Lite(TFLite) vs TensorRT 비교
TensorFlow Lite(TFLite) vs TensorRT 비교 두 기술 모두 AI 모델을 최적화하여 경량화 및 속도 향상을 목표로 하지만, 사용 목적과 동작 방식이 다르다. TensorFlow Lite (TFLite)TensorRT주요 목적모바일 및 엣지 디바이스에서 AI 모델을 위한 경량화NVIDIA GPU에서 딥러닝 모델을 최적화하여 실행 속도 향상지원 플랫폼Android, iOS, Raspberry Pi, 마이크로컨트롤러 등NVIDIA GPU 기반 시스템 (Jetson, 서버 GPU 등)모델 변환 방식Float → Quantization (8-bit, FP16)으로 변환, 경량화FP32 → FP16 또는 INT8 변환으로 속도 향상하드웨어 가속CPU, Edge TPU, GPU, DSP 등 다..
2025.02.27