[논문 정리] Barlow Twins: Self-Supervised Learning via Redundancy Reduction
2021, SSL 관련 논문
https://arxiv.org/abs/2103.03230
Barlow Twins: Self-Supervised Learning via Redundancy Reduction
Self-supervised learning (SSL) is rapidly closing the gap with supervised methods on large computer vision benchmarks. A successful approach to SSL is to learn embeddings which are invariant to distortions of the input sample. However, a recurring issue wi
arxiv.org
Abstract
성공적으로 Self-Supervised Learnging(SSL)을 하려면 입력 왜곡 불변한 임베딩을 학습해야 한다.
이 논문에서는 두 개의 왜곡된 샘플들을 같은 네트워크에 넣어 나온 아웃풋끼리 cross-correlation matrix를 계산하고, identity matrix(단위 행렬)과 가깝게 만드는 방식으로 붕괴(collapse)를 피하는 목적 함수를 제안한다.
이것은 왜곡된 버전의 임베딩 벡터들이 서로 유사하게 만들고, 벡터 요소들 사이의 redundancy(중복성)을 최소화한다.
이 방식은 H. Barlow’s redundancy-reduction principle에 따라 BARLOW TWINS라 부른다.
큰 배치나 네트워크 간의 차이, gradient stopping, moving average on the weight update가 필요하지 않다.
매우 큰 차원의 출력 벡터에 유리하다.
- 왜 Identity Matrix로 만드는가?
- 단위 행렬에 가까워지도록 학습시키는 것은 임베딩 벡터의 중복을 최소화하고 독립성을 유지하기 위한 방법.
- 대각선 성분은 1로 유지되어야 하므로, 같은 차원끼리는 강한 상관성을 가지도록 유도.
- 반면, 비대각선 성분은 0으로 만들어 서로 다른 차원들 간의 상관성을 제거(decorrelation).
- Cross-Correlation Matrix를 단위 행렬로 만드는 목적
- Cross-correlation matrix는 두 네트워크가 출력한 벡터들의 각 차원 간 상관 관계.
- 이 행렬을 단위 행렬에 가깝게 만든다는 것은:
- 같은 차원 간에는 상관성이 높도록 유지(대각선 성분 = 1).
- 다른 차원 간에는 상관성을 최소화(비대각선 성분 = 0).
- 결과적으로, 임베딩 벡터의 각 차원이 독립적이고 고유한 정보를 담도록 보장.
1. Introduction
SSL은 유용한 representation을 인간의 annotation 없이 학습하는 것을 목적으로 한다.
최근의 SSL 기법들은 다양한 왜곡(소위 말하는 'data augmentation')에 불변한 representation을 학습하는 것을 목적으로 한다.
이것은 주로 Siamese networks등을 이용해 다른 왜곡된 버전들의 representation 유사도를 최대화 하는 것으로 얻어진다.
- Constrasive 방식
SIMCLR같은 constrasive 방식은 'positive', 'negative' 샘플 페어를 정의하고 다른 손실 함수로 다룬다. 또한, asymmetric learning 업데이트를 모멘텀 인코더 안에서 사용하여 주 네트워크와 다르게 업데이트한다.
- Clustering 방식
Clustering 방식은 한 개의 왜곡된 샘플로 'target' loss를 구하고, 다른 샘플로 이 타켓을 예측하도록 하며, DEEPCLUSTER(Caron et al., 2018)의 k-평균(k-means) 또는 SWAV(Caron et al., 2020)와 SELA(Asano et al., 2020)의 비미분 가능 연산자(non-differentiable operators)와 같은 대안적인 최적화 방식(alternate optimization scheme)을 적용한다.
BYOL (Grill et al., 2020) and SIMSIAM (Chen & He, 2020) 등의 네트워크는 'predictor' 네트워크를 사용하고, 파라미터 업데이트를 비대칭적으로 한다. 한 개의 입력에 대한 representation을 고정된 target으로 하면서 왜곡된 입력에 대한 네트워크만 업데이트 된다. - asymetry method.
(Chen & He, 2020)은 이런 asymetry 방식의 업데이트, 즉 stop gradient가 *trivial solation(사소한 해)를 방지하는데 중요하다고 주장한다.
* 사소한 해(trivial solutions): 입력 데이터에 상관 없이 모델이 항상 같은 출력을 내는 등 의미 있는 학습 결과를 내지 못하는 상태.
이 논문에서는 BARLOW TWINS라는 redundancy reduction 이론을 적용한 SSL 방식을 제안한다.
이 이론을 주장한 H. Barlow는 신호 처리의 목표는 매우 중복적인 신호 입력을 factorial code(통계적으로 독립적인 성분)으로 재코딩(recode)하는 것이라는 가설을 세웠다. 이 이론은 수많은 SSL 관련 방식을 파생시켰다.
이 이론에 입각하여, 필자는 twin embeddings로부터 계산된 cross correlation matrix가 단위 행렬(Identity Matrix)에 가까워지도록 만드는 목적 함수를 제안한다. 이는 개념적으로 간단하고 쉬우며, 사소한 해 문제에도 유용하다.
다른 방식과 비교하면, prediction networks 등의 비대칭적 메커니즘, 모멘텀 인코더, non-differentiable operators, stop-gradient 등의 큰 배치가 필요하지 않는다. 매우 큰 차원의 임베딩에 유효하다.
2. Method
2.1. Description of BARLOW TWINS
다른 SSL 방식처럼, BARLOW TWINS도 왜곡된 이미지에 joint embedding을 수행한다. 이것은 모든 배치 $X$ 의 이미지에 대해 두 개의 distored views를 생산한다.
Distored view는 data augmentation $\tau$ 의 distribution에 의해 얻어진다.
Distorted view $Y^A$, $Y^B$ 배치는 함수 $f_{\theta}$로 들어가서 배치 임베딩 $Z^A$, $Z^B 를 만든다. 여기서 함수는 학습 가능한 파라미터 $\theta$를 가진 딥러닝 네트워크다.
표기법을 단순하하기 위해, $Z^A$, $Z^B$는 배치 차원에서 평균 중심화(mean-centered)되었다고 가정한다. 따라서 각 유닛은 배치에 걸쳐 평균 출력이 0이 된다.
* 평균 중심화: 배치 내에서 데이터의 평균 값을 0으로 만드는 과정. (Batch-Norm 얘기하는 듯..?)
BARLOW TWINS는 다음과 같은 특수한 loss function을 사용한다.

- 첫 번째 항 (invariance term):
- $(1−C_{ii})^2: cross-correlation matrix $C$의 대각선 성분 $C_{ii}$가 1에 가까워지도록.
- 이는 두 네트워크의 출력이 동일한 정보를 학습하도록 보장.
즉, 두 네트워크가 같은 데이터를 표현하는 것을 목표.
- 두 번째 항 (redundancy reduction term):
- ${C_{ij}}^2: 교차 상관 행렬의 비대각선 성분을 최소화.
- $\lambda$:
- 두 항의 중요도를 조절하는 양의 상수.
- 첫 번째 항(invariance)과 두 번째 항(redundancy reduction) 사이의 균형을 맞춘다.
직관적으로, invariance term은 cross-correlation matrix의 대각 성분이 1과 같게 되도록 노력하며, 임베딩 불변성이 왜곡에도 적용되도록 한다.
redundancy reduction term은 대각이 아닌 성분들을 0과 같도록 만들어 임베딩의 다른 벡터 요소들 사이를 decorrelation 한다. 이 decorrelation은 출력 유닛 간의 redundancy(중복성)을 줄여 출력 유닛이 non-redundant 정보를 갖게 한다.
BARLOW TWINS의 목적함수는 정보이론의 시각에서 볼 수 있고, 특히, Information Bottleneck (IB) objective의 일부 변수이다. SSL에 적용하면, IB 목적 함수는 왜곡 특화된 정보는 최소화 하면서 풍부한 정보를 보전하는 representation을 찾는 것이다.
BARLOW TWINS의 redundancy reduction term은 constrasive term과 비슷한 역할을 한다.
중요한 개념적 차이는 우리 방식의 실용적인 이점을 보여준다.
- 많은 양의 negative 샘플이 필요하지 않아 작은 배치로도 학습이 가능하다.
- 큰 차원의 임베딩에서 유리하다.
redundancy reduction term은 임베딩에 soft-whitening 제약을 걸은 것으로 보여질 수 있고, 이를 우리의 방식과 연관시키면 hard-whitening 제약을 걸 수 있다. 하지만, 우리의 방식은 최신 hard-whitening 기법보다 뛰어나다.
2.2. Implementation Details
Image Augmentation
입력 이미지는 변형되어 왜곡된 이미지 두 개를 생성한다. 이미지 증강 파이프라인은 다음과 같은 구성이다:
random cropping, resizing to 224 × 224, horizontal flipping, color jittering, converting to grayscale, Gaussian blurring, and solarization.
Cropping and resizing은 항상 적용되고, 나머지는 어떤 확률에 의해 랜덤하게 적용된다. (BYOL과 파라미터 같음.)
Architecture
인코더는 ResNet-50, 마지막 classification layer 제외, 2,048 output units.
그 다음 projector network. 이는 세 개의 linear layers이고 각 8,192 output units. 처음 두 개의 레이어는 batch normalization layer와 rectified linear 유닛(ReLU)이 적용됨.
인코더의 출력은 'representation'이라 부르고, projector의 출력은 'embeddings'라 부른다. Representation은 downstream tasks에 사용되며, embeddings는 loss function에 들어간다.

Optimization
최적화 프로토폴은 BYOL (Grill et al., 2020)을 따라함.
- LARS optimizer (You et al., 2017) and train for 1000 epochs with a batch size of 2048.
그럼에도, 작은 배치 사이즈(예, 256)에서도 학습이 잘 된다는 것을 강조.
- learning rate of 0.2 for the weights and 0.0048 for the biases and batch normalization parameters.
- multiply the learning rate by the batch size and divide it by 256.
- learning rate warm-up period of 10 epochs, after which we reduce the learning rate by a factor of 1000 using a cosine decay schedule (Loshchilov & Hutter, 2016).
- λ = $5 · 10^3$
- weight decay parameter of $1.5 · 10^6$ .
- biases and batch normalization parameters are excluded from LARS adaptation and weight decay.
- 32 V100 GPUs and takes approximately 124 hours.
3. Results
기본적인 실험 + representation을 이용한 다른 데이터셋으로의 transfer learning도 적용.
ImageNet ILSVRC-2012 dataset에 SSL된 pretrained 네트워크 사용.
Image classification, object detection에 평가.
3.1. Linear and Semi-Supervised Evaluations on ImageNet
Linear evaluation on ImageNet
우리의 방식을 사용해 학습된 ResNet-50의 최상단 fixed representation위에 ImageNet 데이터를 이용해 Linear classifier를 학습.
ResNet-50을 사용하는 인코더 중에서 Top-1 SOTA.

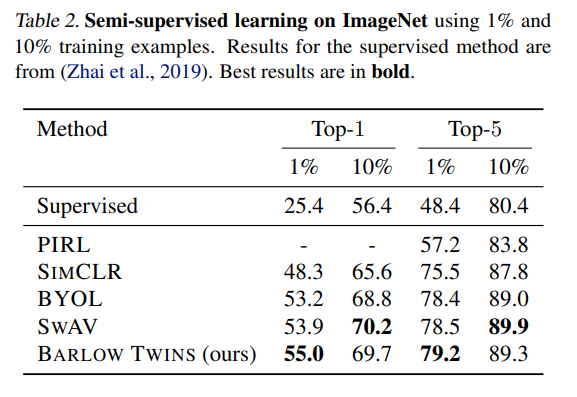
Semi-supervised training on ImageNet
ResNet-50 pretrained를 우리의 방식으로 fine-tuned. 성능 다른 방식과 비슷하거나 조금 더 높다.
3.2. Transfer to other datasets and tasks
Image classification with fixed features
고정된 representation에 linear classifier 학습. 성능 다른 방식과 비슷하거나 조금 더 높다.

Object Detection and Instance Segmentation
Localization based task에도 실험. SOTA이다.

4. Ablations
Loss Function Ablations
우리의 각 loss term에 대해 검증 + 다른 유명한 SSL loss 실험.
Invariance term(on-diagonal term)이나 redundancy reduction term을 지우는 것은 우리의 loss function이 나쁜 결과를 나타냄.
그래서 다른 정규화 방식을 연구함. Feature dimension에서 임베딩을 정규화(normalization) 하는 것은 그것이 unit sphere 위에 있게 만들어 cosine similarity를 측정할 수 있게 한다.
첫 번째로, Batch/feature dimension에서 평균을 빼는 방식으로 임베딩을 정규화하는 방식과, 정규화되지 않은 covariance matrix를 정규화된 cross-correlation matrix대신 사용하는 방식을 실험했다. 성능은 다소 감소함.
두 번째로, projector의 batch-norm을 지우는 실험을 진행, 미묘한 효과가 있음.
세 번째로, projector의 batch-norm을 지우고, cross-correlation matrix를 covariance matrix로 바꿈. 이는 batch dimension에서 feature가 정규화되지 않음을 의미함. 성능은 다소 감소.
마지막으로, cross-entropy loss with temperature를 on-diagonal term과 off-diagonal term에 적용, 성능은 다소 감소.
Robustness to Batch Size
배치사이즈를 줄이는 실험을 하기 위해, grid search on LARS learning rates for each batch size 수행.
실험 결과 배치를 256까지 줄여도 영향이 거의 없음.
작은 배치 사이즈면서 non-constrasive 방식은 우리의 방식이 실용적이라는 것을 보여줌.
Effect of Removing Augmentations
우리의 방식은 일부 augmentation을 제거하면 성능이 떨어지나, BYOL과 비교했을 때 일정 왜곡 케이스에서는 우리가 더 우수함. BYOL for which the invariances learned seem generic and intriguingly independent of the specific distortions used. (라고 하는데 이게 더 좋은거 아닌가??????? 왜곡과 독립적이면 좋은거 아님..?)
Projector Network Depth & Width
다른 SSL 네트워크는 projector network가 ResNet ouput의 차원을 크게 줄인다.
이와는 다르게, 우리는 BARLOW TWINS이 projector output의 차원이 매우 클 때 성능이 좋다는 것을 발견했다. 다른 방식은 출력 차원이 클 수록 빨리 saturate 되었다. 그러나, 우리의 모델은 모든 아웃풋 차원에서 발전된 모습을 보였다. 이것은 ResNet의 output은 2048으로 고정되어 있기 때문에, 우리의 모델안에서 dimensionality bottleneck처럼 작용하며, intrinsic dimensionality of the representation의 제한을 둔다. (= ResNet은 차원이 고정되어 있어서 출력 차원이 커질수록 병목 현상이 존재함에도 불구하고, 제안된 모델은 성능이 계속 향상된다.)

근데 출력 차원이 작으면 오히려 성능이 엄청 떨어지네..
Breaking Symmetry
많은 SSL 방식들은 다른 symmetry-breaking mechanisms을 사소한 해(trivial solutions)를 피하기 위해 사용한다. 제안된 loss function은 이런 문제를 구조적으로 해결한다. 다른 모델들처럼 비대칭적 매커니즘을 사용할 때 성능은 더 낮아진다.
- 비지도 학습의 사소한 해 문제
SSL에서 학습 과정이 적절히 설계되지 않으면 모든 출력이 동일해질 수 있음.
이를 trivial solutions라고 하며, 이러한 결과는 모델이 유용한 표현(representation)을 학습하지 못했다는 것을 의미.
- 대칭 파괴가 필요한 이유
많은 SSL 방법은 두 개의 입력(예: 같은 이미지를 다른 왜곡 변형으로 처리한 것)을 네트워크에 입력하여 학습.
만약 두 입력이 완전히 동일하게 처리되도록 학습된다면, 네트워크는 유용한 표현 대신 단순히 두 입력을 동일하게 만드는 쪽으로 수렴할 가능성이 높다. 이를 막기 위해 대칭을 깨뜨리는 메커니즘이 필요.
1. BYOL (Bootstrap Your Own Latent): Stop-gradient 메커니즘 사용
- 타겟 네트워크를 업데이트하지 않고 고정(stop-gradient), 두 네트워크 간 대칭을 깨뜨린다.
- 두 네트워크가 단순히 동일한 출력을 내는 것을 방지, 더 유용한 표현을 학습.
2. SIMSIAM (Simple Siamese): Stop-gradient + Asymmetry in architecture
- stop-gradient + 두 네트워크 중 하나에만 추가적인 예측기를 사용하여 대칭 구조를 깨뜨림.
3. SWAV (Swapping Assignments): Cluster assignment (군집 할당)
- 군집화(clustering)를 통해 대칭성을 깨뜨림.
- 각 데이터 포인트를 클러스터로 할당하여, 모델이 단순히 동일한 출력을 내지 않도록.

5. Discussion
BARLOW TWINS는 self-supervised representations를 joint embedding과 임베딩 벡터 사이의 유사도를 높이는 목적함수, 요소간 중복성 감소를 통해 학습한다.
제안된 방식은 큰 배치 샘플과 다른 비대칭적 twin 네트워크를 필요로 하지 않는다.
5.1. Comparison with Prior Art
infoNCE
The INFONCE loss, where NCE stands for Noise-Contrastive Estimation (Gutmann & Hyvarinen ¨ , 2010), is a popular type of contrastive loss function used for self-supervised learning.
이것은 다음의 수식으로 나타낼 수 있다.

비교를 위해, BARLOW TWINS도 같은 명명으로 나타내면 다음과 같다.

둘 다 첫 번째 항은 왜곡 불변 임베딩을 만드는 것이 목적이고, 두 번째 항은 임베딩의 다양성을 최대화 하는 것이 목적이다. 또한, 둘 다 배치 통계(batch statistics)을 변동성(variability)를 측정하는데 사용한다.
그러나, INFONCE는 임베딩 변동성 최대화를 모든 샘플 사이의 pairwise distance를 최대화 하는 방식이고, 제안된 방식은 임베딩 벡터 요소를 decorrelating 하는 방식이다.
INFONCE의 constrasive term은 non-parametric estimation of the entropy of the distribution of embeddings로 해석될 수 있다. 이것의 문제점은 낮은 차원의 세팅과 많은 양의 샘플이 있을 때만 안정적이라는 것이다.
- 임베딩 분포(distribution of embeddings):
- 모델이 학습한 임베딩들이 고차원 공간에서 어떻게 분포되어 있는지를 의미.
- 비슷한 입력 데이터는 가까운 위치에, 서로 다른 데이터는 멀리 떨어지도록 분포.
- 엔트로피
- 확률 분포의 다양성이나 불확실성을 나타내는 척도.
- 분포가 다양하면 엔트로피가 높고, 분포가 집중되면 엔트로피가 낮다.
- 임베딩 분포가 고르게 퍼져 있다면 → 엔트로피가 높음.
- 임베딩이 한 지점에 몰려 있다면 → 엔트로피가 낮음.
- 임베딩 분포의 엔트로피는 다음과 같은 이유로 중요:
- 다양한 표현 학습: 엔트로피가 높으면 임베딩이 다양한 입력 데이터를 더 잘 표현.
- 모델 붕괴 방지: 모든 데이터가 동일한 임베딩으로 학습되는 문제(사소한 해)를 방지.
- non-parametric은 확률 분포를 추정할 때 특정한 분포 형태(예: 가우시안 분포)를 가정하지 않고, 데이터 자체를 기반으로 계산하는 방법.
- 임베딩 분포의 엔트로피 non-parametric 추정 방법:
- 모델이 학습하는 과정에서 배치(batch) 내 데이터 간의 관계를 사용.
- INFONCE 손실 함수에서 대조 항(contrastive term)은 배치 내의 양성 샘플(positive sample)과 음성 샘플(negative sample) 간의 유사도를 계산합니다.
- 이를 통해 데이터 간의 상호작용을 기반으로 임베딩의 분포를 간접적으로 추정.
이와 대조적으로, 제안된 방식은 proxy 엔트로피를 Gaussian parametrization 안에서 estimator of the distribution of embeddings로 사용한다고 해석할 수 있다. 이러한 간소화된 parametrization 덕분에 임베딩의 다양성이 더 적은 샘플과 큰 차원의 임베딩에서도 잘 추정될 수 있다. 제안된 방식이 small batch에서 성능이 높은 이유이다.

그 외에도 INFONCE와 여러 차이점이 있다:
- INFONCE는 feature dimension에서, 이 방식은 batch dimension에서 정규화.
- 제안된 방식은 얼마나 invariance term을 강조할 것인지 결정하는 파라미터 람다 있음.
- INFONCE도 temperature, non-parametric kernel density estimation of entropy안의 커널 너비로 해석되는, 하이퍼파라미터를 갖고있다. 이는 실질적으로 배치 내에서 어려운 negative sample의 상대적 중요도를 조정한다.
Asymmetric Twins
BOOTSTRAP-YOUR-OWN-LATENT (aka BYOL) (Grill et al., 2020) and SIMSIAM은 어떤 constrastive term 없이 twin embeddings 사이의 코사인 유사도를 목적함수로 사용하는 기법이다.

이 방식은 사소한 해 문제를 비대칭적 학습으로 해결했다. 예를 들어, BYOL은 predictor network를 사용해 대칭 구조를 파괴하고, exponential moving average를 target network의 weight 업데이트로 사용하여 느린 업데이트를 진행했다. 이런 매커니즘은 사소한 해 문제를 잘 해결한다.
최근 연구 (Chen & He, 2020)는 moving average가 필수적이지 않으며, stop-gradient와 predictor network는 붕괴를 박는 중요한 요소라는 것을 보여주었다. 다른 연구는 batch normalization이나 다른 group normalization이 붕괴를 피하는 것의 중요한 요소라는 것을 보여준다.
우리의 방식처럼, 이런 비대칭적 방식은 샘플간의 상호작용이 없기 때문에 큰 배치를 필요로 하지 않는다.
비대칭 방식은 일반적인 손실 함수 최적화(최소화 혹은 최대화)로 설명하기 어렵기 때문에 학습 목적 자체에 사소한 해가 존재하지만, 이를 피하기 위해 stop-gradient 등의 기술을 사용한다.
이와는 반대로 제안된 방식은 구조적으로 이를 해결하기 때문에 개념적으로 더 간단하고 실용적이다.
Whitening
최근의 연구는 W-MSE 제안. 코사인 유사도를 계산하기 전, 배치 임베딩에 whitening operation 수행. 앞으로 발전 가능성이 있는 분야.
Clustering
DEEPCLUSTER (Caron et al., 2018), SWAV (Caron et al., 2020), SELA는 constrasive 비슷한 비교 수행.
동시적으로 데이터를 군집화. 붕괴하기 쉽다.
5.2. Future Directions
제안된 모델은 SSL을 위한 information bottle의 방법으로 사용될 수 있다.
알고리즘을 좀 더 수정하면 발전 가능성이 있다. 예를 들어, 단일 네트워크의 auto-correlation matrix 비대각성분을 redundancy reduction term으로 사용할 수도 있다.

- 끝 -



